
Naszym zadaniem będzie implementacja funkcji, która będzie wykorzystywac metodę liniowych najmniejszych kwadratów, aby znaleźć podstawową liczbę odtwarzania dla przypadków COVID-19 w Polsce.
W naszym (niezmiernie uproszczonym i nie nadającym się do zastosowań praktycznych, ale ilustrującym kluczowe idee) modelu, przyjmiemy, że początkowy rozwój wirusa w populacji rośnie wg wykładniczego wzrostu:
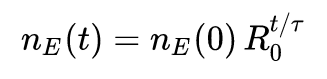
gdzie t oznacza czas (w dniach), n_E(t) oznacza liczbę osób chorych w momencie t, R_0 jest szukaną podstawową liczbą odtwarzania, zaś \tau przyjmiemy za równą 1.
Nasz program będzie wykorzystywał fakt, że to równanie po obustronnym zlogarytmowaniu staje się liniowe:
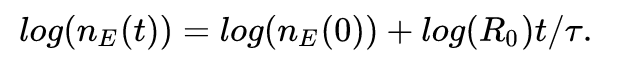
Jeśli mamy dane o liczbie potwierdzonych chorych w pewnym okresie (dla każdego kolejnego dnia), znamy \tau, to możemy wykorzystać liniową ważoną metodę najmniejszych kwadratów do dopasowania rozwiązania, aby znaleźć log(R_0).
Warto pamiętać, że w tym przypadku, jeśli nie zastosujemy wag w metodzie najmniejszych kwadratów, nasza metoda będzie minimalizować |log(x)-log(b)|^2, co nie będzie prawidłowe. Jak widać na poniższym rysunku, dopasowanie do danych jest lepsze (zwłaszcza z prawej strony) dla problemu ważonego.
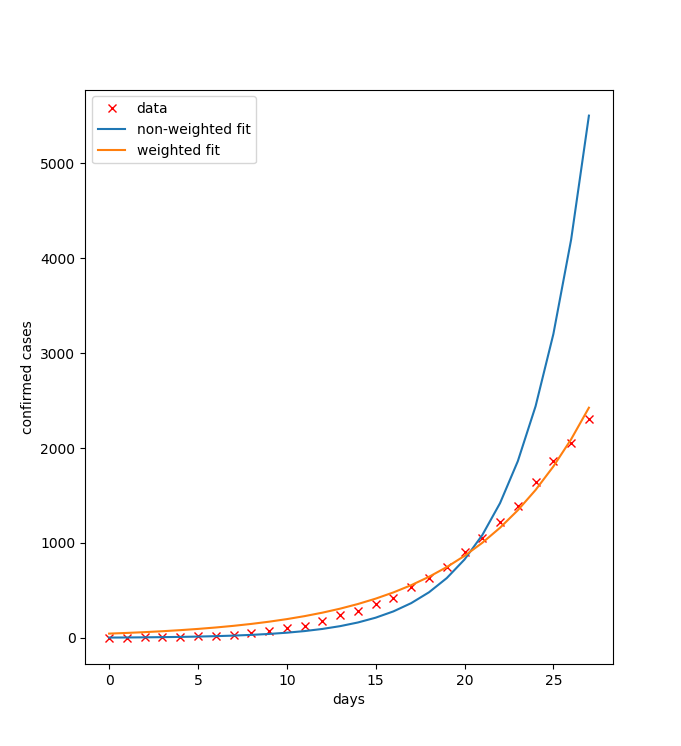 Dlatego warto przypomnieć sobie zadanie o ważonym zagadnieniu liniowych największych kwadratów, które ma podane rozwiązanie w materiałach do metod numerycznych. W naszym przypadku wagi w_i są równe n_E(i).
Dlatego warto przypomnieć sobie zadanie o ważonym zagadnieniu liniowych największych kwadratów, które ma podane rozwiązanie w materiałach do metod numerycznych. W naszym przypadku wagi w_i są równe n_E(i).
Punktacja:
- Napisanie funkcji wykorzystującej funkcję scipy.linalg.lstsq (proszę nie używać funkcji typu polyfit) i obliczającej ważony liniowy problem najmniejszych kwadratów (5 pktów)
- Napisanie funkcji wykorzystującej funkcję urlopen() i dane dostępne publicznie aby pobrać pierwsze 28 dni, kiedy w wybranym kraju (np. Polsce) występowały zachorowania (tj. pomijając pierwsze zera w linii odpowiadającej danemu krajowi) (5 pktów)
- Napisanie programu, który wykorzystuje te dane, aby obliczyć R_0 zgodnie z wzorami podanymi powyżej. Program powinien też generować wykres podobny do powyższego. (5 pktów)
Rozwiązania należy nadsyłać w ciągu dwóch tygodni (czyli do 13. maja włącznie) na mój adres e-mail z dopiskiem [ONA-2] w tytule. Jak zwykle, proszę o skomentowane pliki .py jako normalne załączniki.
Zgodnie z tym co mówiłem podczas wykładu, można używać pakietu pandas do wczytywania pliku CSV, ale można też używać po prostu funkcji readlines() i metody .split() na napisach.
W którym miejscu, używając pakietu pandas powinniśmy wówczas zastosować funkcję urlopen? Mam wrażenie, że pd.read_csv jest samowystarczalne bez tej funkcji. Skłaniałabym się jednak bardzo do używania tego pakietu ze względu na podział w danych na prowincje/stany, co przy Polsce nie ma znaczenia, jednak przy Chinach mogłoby nam wypluwać różne kruczki, które rozwiąże pd.groupby.
Oryginalne zadanie nie zawierało żadnego odniesienia do pakietu pandas, więc zalecało urlopen() do pobrania danych. Jeśli korzysta Pani z pandas, może Pani otwierać pliki zdalne, więc nie musi pani korzystać z urlopen()
Jeszcze jeden komentarz wynikający z pytań jednego ze słuchaczy. Wartość n_e(0) jest w modelu parametrem a równania a*R^t. Jeśli Państwo założą, że w związku z tym można po prostu wstawić wartość z pierwszego dnia i nie szukać tego współczynnika, to ograniczają Państwo przestrzeń modeli. Przypominam, że szukamy modelu, w którym również pomiar liczby chorych pierwszego dnia może być błędny, co oznacza, że parametr a jest szukaną, a nie daną.
Czy mamy napisać program tylko dla danych z Polski, czy to osoba odpalającą program ma mieć możliwość wyboru państwa z danych?
W opisie mowa jest o ‘wybranym kraju’, idealnie jeśli użytkownik może go wybrać podczas uruchomienia
Czy w związku z tym mamy też ignorować równanie dla pierwszego dnia podczas szukania współczynników funkcji, ponieważ dla niego wagą powinno być nE(0), które zakładamy, że może być błędne?
Wszystkie pomiary mogą być różne od modelu i mogą być też błędne, choć to dwie różne sprawy są. Jak w każdym przypadku dopasowania danych do modelu, szukamy najlepszego modelu jeśli chodzi o dopasowanie do danych. Jeśli Państwo uznaliby, że nE(0) jest już gotowym parametrem modelu, to przypisywaliby Państwo temu kokretnemu punktowi danych wagę nieskończenie wielką. Natomiast dopasowywanie tego parametru nie wyklucza stosowania wagi. Nie warto brać pomiarów zerowych, ale takich tam być nie powinno
Czy wagi w zadaniu powinny być równe liczbie przypadków czy logarytmowi z liczby przypadków?
Liczbie przypadków.
Czy obrazek, który Pan zamieścił odpowiada danym z Polski?
Tak, choć moje dane pochodziły z innego źródła i mogą niewiele różnić się od tych, które Państwo pobierają. Nie mniej zasadniczo, obraz powinien być podobny, mimo jakichś drobnych odchyleń.
Czy “wykres podobny do powyższego” oznacza, że powinniśmy rozwiązać również problem nieważony, czy wystarczy część bez niebieskiej linii?
Wystarczą dwie linie.